At ValidExamDumps, we consistently monitor updates to the Microsoft DP-100 exam questions by Microsoft. Whenever our team identifies changes in the exam questions,exam objectives, exam focus areas or in exam requirements, We immediately update our exam questions for both PDF and online practice exams. This commitment ensures our customers always have access to the most current and accurate questions. By preparing with these actual questions, our customers can successfully pass the Microsoft Designing and Implementing a Data Science Solution on Azure exam on their first attempt without needing additional materials or study guides.
Other certification materials providers often include outdated or removed questions by Microsoft in their Microsoft DP-100 exam. These outdated questions lead to customers failing their Microsoft Designing and Implementing a Data Science Solution on Azure exam. In contrast, we ensure our questions bank includes only precise and up-to-date questions, guaranteeing their presence in your actual exam. Our main priority is your success in the Microsoft DP-100 exam, not profiting from selling obsolete exam questions in PDF or Online Practice Test.
You manage an Azure Machine Learning workspace. The development environment tor managing the workspace is configured to use Python SDK v2 in Azure Machine Learning Notebooks A Synapse Spark Compute is currently attached and uses system-assigned identity You need to use Python code to update the Synapse Spark Compute 10 use a user-assigned identity.
Solution: Configure the IdentityConfiguration class with the appropriate identity type. Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it as a result, these questions will not appear in the review screen.
You use Azure Machine Learning designer to load the following datasets into an experiment:
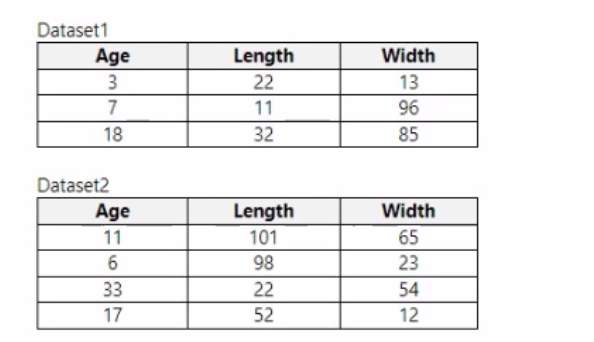
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Apply Transformation module.
Does the solution meet the goal?
You have an Azure Machine Learning workspace named Workspace 1 Workspace! has a registered Mlflow model named model 1 with PyFunc flavor
You plan to deploy model1 to an online endpoint named endpointl without egress connectivity by using Azure Machine learning Python SDK vl
You have the following code:
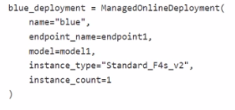
You need to add a parameter to the ManagedOnllneDeployment object to ensure the model deploys successfully
Solution: Add the with_package parameter.
Does the solution meet the goal?
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
AUC_weighted is a Classification metric.
Note: AUC is the Area under the Receiver Operating Characteristic Curve. Weighted is the arithmetic mean of the score for each class, weighted by the number of true instances in each class.
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-understand-automated-ml
You train and register an Azure Machine Learning model
You plan to deploy the model to an online endpoint
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a managed online endpoint and set the value of its auth.mode parameter to aml.token. Deploy the model to the online endpoint.
Does the solution meet the goal?